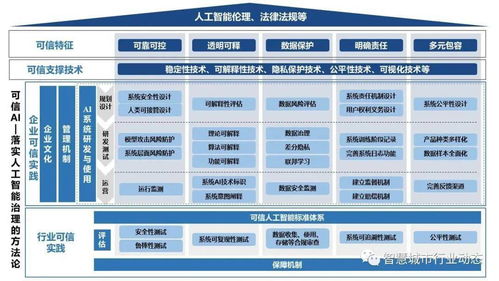
随着人工智能技术的深度渗透与广泛应用,构建安全、可靠、可控的“可信人工智能”已成为业界共识与迫切需求。作为实现可信AI的核心载体,人工智能基础软件(尤其是AI框架)在其中扮演着枢纽角色。一个真正“可信”的AI框架,不仅需要提供高效的模型开发与训练能力,更需内嵌一套完整的技术体系来保障其全生命周期的可信赖性。本文将深入解析支撑可信AI框架的四大关键技术,并探讨其实践路径。
一、四大支撑技术
- 安全与隐私保护技术
- 核心技术:这主要包括联邦学习、差分隐私、同态加密与安全多方计算。联邦学习使得数据可以“可用不可见”,在本地进行模型训练,仅交互加密的模型参数更新,从而保护原始数据隐私。差分隐私通过在数据或查询结果中添加可控的随机噪声,防止从模型输出中反推个体信息。同态加密允许在密文状态下直接进行计算,而安全多方计算则使多个参与方能在不泄露各自私有输入的前提下,共同完成函数计算。
- 在框架中的体现:可信AI框架需将这些技术作为基础算子或专用模块进行集成,提供标准化的API,使开发者能够便捷地将隐私保护能力嵌入到数据预处理、模型训练与推理的各个环节。
- 鲁棒性与可解释性技术
- 核心技术:对抗性鲁棒性旨在提升模型抵御精心设计的对抗样本攻击的能力,技术包括对抗训练、输入净化等。可解释性技术则致力于揭开模型“黑箱”,包括基于特征归因的方法(如SHAP、LIME)、可视化工具以及生成易于理解的决策规则或自然语言解释。
- 在框架中的体现:框架应内置对抗样本生成与检测工具、鲁棒性训练接口,并提供模型诊断仪表盘,可视化展示特征重要性、决策路径及潜在的偏见来源,辅助开发者理解、调试并加固模型。
- 公平性与偏见消减技术
- 核心技术:涉及公平性度量(如 demographic parity, equal opportunity)、偏见检测与消减算法。通过在数据层面(重采样、重加权)、算法层面(如 adversarial debiasing)或后处理层面调整决策阈值,来减少模型对特定敏感属性(如性别、种族)的歧视性偏差。
- 在框架中的体现:可信AI框架需要集成公平性评估指标库,提供从数据审计到模型训练、评估、校正的全流程工具链,自动化或半自动化地帮助识别和缓解不公平性。
- 可控与可追溯的治理技术
- 核心技术:主要指模型版本管理、数据谱系追溯、全生命周期监控以及符合伦理规范的约束嵌入。利用区块链等技术实现关键操作(如数据使用、模型更新)的不可篡改记录。
- 在框架中的体现:框架需与MLOps平台深度结合,提供完善的元数据管理、实验追踪、模型注册和部署监控功能。确保从训练数据来源、参数配置、到模型部署后性能漂移的每一个环节都可审计、可追溯、可回滚。
二、实践路径
构建与落地可信AI框架并非一蹴而就,需要遵循系统化的实践路径:
- 分层融入,标准先行:将上述四大技术能力以“基础层算子(如加密原语)- 中间件组件(如联邦学习模块)- 顶层工具链(如可视化审计工具)”的分层架构融入框架设计中。积极采纳和参与制定行业与国家标准(如IEEE、ISO相关标准),确保技术实践的规范性与互操作性。
- 开发运维一体化(DevSecOps for AI):将可信性要求贯穿于AI系统的整个开发运维(DevOps)周期,形成“AI DevSecOps”。在需求设计阶段即引入隐私、公平性影响评估;在开发阶段利用框架内置工具进行安全编码与测试;在部署与运维阶段持续监控模型性能与可信指标。
- 场景驱动,渐进式实施:针对不同应用场景(如金融风控、医疗诊断、自动驾驶)的风险等级与监管要求,优先实施最关键的可信技术。例如,金融领域优先强化隐私保护与可解释性;公共决策领域则优先保障公平性与可追溯性。从试点项目开始,积累经验后再逐步推广。
- 生态共建,开放协作:可信AI的实现需要算法研究者、框架开发者、行业用户、法律与伦理专家的多方协作。开源框架应建立开放的治理社区,鼓励贡献可信功能模块、共享最佳实践案例,并建立第三方审计与认证机制,共同推动可信AI生态的繁荣。
###
可信AI框架是人工智能行稳致远的“压舱石”。其四大支撑技术——安全隐私、鲁棒可解释、公平无偏见、可控可追溯——共同构成了一个相互关联、彼此增强的技术矩阵。通过分层融入、标准引领、全周期治理、场景化落地与生态协作的实践路径,我们能够稳步推进可信AI从理论原则走向工程现实,最终让人工智能技术真正造福社会,赢得广泛信任。