随着生物技术与信息技术的深度融合,人工智能(AI)在新药研发领域展现出巨大潜力,尤其是在多肽药物分析这一前沿方向。山东大学软件工程专业2019级的学生,在“软件工程应用与实践”课程中,深入探索了“基于人工智能的多肽药物分析”这一课题,并聚焦于其核心环节——人工智能基础软件的开发。这一实践项目不仅是对学生专业知识的综合检验,也是对前沿科技服务生命健康的一次有益尝试。
一、 项目背景与意义
多肽药物因其高活性、高特异性及较低的毒副作用,已成为药物研发的热点。多肽序列空间庞大,其结构与功能关系复杂,传统的实验筛选方法耗时费力且成本高昂。人工智能技术,特别是机器学习和深度学习,能够从海量的生物数据中学习规律,预测多肽的活性、毒性、溶解性、稳定性等关键性质,从而极大地加速先导化合物的发现与优化进程。
本项目的核心目标,是开发一套服务于多肽药物分析的人工智能基础软件。它旨在为研究人员提供一个集数据预处理、模型构建、训练评估和预测应用于一体的工具平台,降低AI技术在生物医药领域应用的门槛。
二、 核心开发内容
软件开发团队遵循软件工程规范,将项目分解为以下几个关键模块:
- 数据集成与管理模块:从公开数据库(如UniProt、PeptideDB)或合作实验室获取多肽序列及其理化、活性标注数据。开发了高效的数据清洗、标准化和特征工程(如氨基酸组成、理化性质描述符、序列编码等)流水线,为模型训练提供高质量输入。
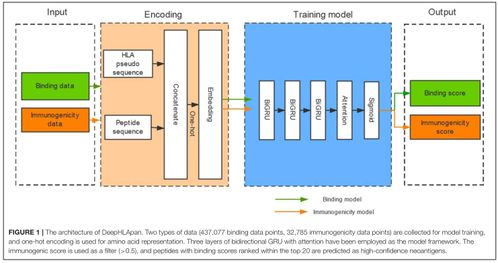
- 机器学习算法库模块:集成并实现了适用于多肽分析的经典机器学习算法(如支持向量机SVM、随机森林Random Forest)以及前沿的深度学习模型(如循环神经网络RNN、长短期记忆网络LSTM、注意力机制模型、图神经网络GNN等)。模型能够处理序列数据,并预测结合亲和力、抗菌活性、细胞穿透性等多种属性。
- 模型训练与调优平台:提供可视化的交互界面,允许用户选择数据、算法,并灵活设置超参数。平台集成了交叉验证、网格搜索、早停法等策略,辅助用户高效地进行模型训练与性能优化,自动记录实验过程与结果。
- 预测与可视化分析模块:用户输入新的多肽序列,系统可利用训练好的模型快速进行性质预测。结果以图表(如活性概率分布、特征重要性排序)和报告的形式直观呈现,辅助研究人员进行决策。
- 系统架构与部署:采用微服务架构,前后端分离。后端使用Python(TensorFlow/PyTorch, Scikit-learn框架),提供RESTful API;前端采用Vue.js等框架构建用户友好界面。项目最终可部署于本地服务器或云端,便于协作与扩展。
三、 实践挑战与解决方案
在开发过程中,团队遇到了诸多挑战:
- 数据不均衡与噪声:通过过采样、欠采样以及合成少数类过采样技术(SMOTE)等算法进行数据平衡,并结合领域知识进行噪声过滤。
- 模型可解释性:集成SHAP、LIME等可解释性AI工具,帮助生物学家理解模型的预测依据,增加结果的可信度。
- 计算资源限制:优化数据加载与模型结构,利用GPU加速训练,并设计缓存机制提升响应速度。
- 跨学科理解:团队成员积极与生物、药学背景的师生沟通,确保软件功能切实符合领域分析需求。
四、 项目成果与展望
通过本次“软件工程应用与实践”,团队成功交付了一个功能相对完整、具备良好可用性的AI多肽分析基础软件原型。它不仅锻炼了学生在需求分析、系统设计、算法实现、团队协作和项目管理方面的综合能力,更产出了具有潜在应用价值的软件成果。
该软件可以从以下几方面持续深化:
- 算法深化:集成更先进的预训练语言模型(如蛋白质语言模型),提升预测精度与泛化能力。
- 功能扩展:增加多肽从头设计、优化建议生成等生成式AI功能。
- 生态建设:与湿实验平台对接,形成“计算预测-实验验证”的闭环,真正推动多肽药物的发现。
###
山东大学2019级软件工程专业的此次实践,是“新工科”建设与“医工结合”趋势下的一个生动案例。它将人工智能、软件工程与生物医药前沿问题紧密相连,培养了学生解决复杂跨学科实际问题的能力。所开发的“基于人工智能的多肽药物分析基础软件”,既是对所学知识的创造性应用,也为人工智能赋能新药研发贡献了一份年轻的智慧与力量,展现了当代学子面向国家重大需求进行科技创新实践的担当。