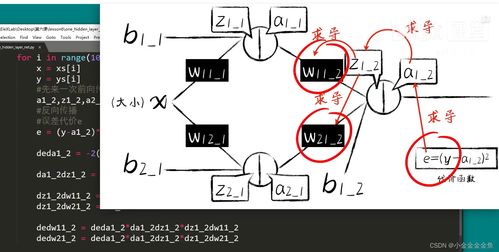
随着人工智能技术的飞速发展,深度学习已成为图像超分辨率(Super-Resolution, SR)领域的关键驱动力,显著提升了从低分辨率图像重建高分辨率图像的视觉质量与细节恢复能力。高效稳定的人工智能基础软件则为这些模型的研发、部署与应用提供了不可或缺的支撑。本文将重点介绍深度学习在超分辨率领域的九个代表性模型,并探讨其与人工智能基础软件开发之间的紧密联系。
一、深度学习超分辨率九大代表性模型
- SRCNN(Super-Resolution Convolutional Neural Network):作为深度学习在超分辨率领域的开创性工作,SRCNN首次将三层卷积神经网络应用于图像超分辨率,通过端到端的学习直接学习低分辨率到高分辨率的映射函数,奠定了后续研究的基础。
- FSRCNN(Fast Super-Resolution Convolutional Neural Network):针对SRCNN计算量大的问题,FSRCNN在网络的起始和结束部分分别引入了特征收缩与扩张层,并使用了更小的卷积核和更深的网络结构,在保持性能的同时大幅提升了推理速度。
- ESPCN(Efficient Sub-Pixel Convolutional Neural Network):该模型提出了亚像素卷积层(Sub-Pixel Convolution Layer),特征提取过程在低分辨率空间进行,最后通过亚像素卷积操作将特征图重组为高分辨率图像,极大降低了计算复杂度。
- VDSR(Very Deep Super Resolution):VDSR通过引入残差学习的思想和极深的网络结构(20层),专注于学习高分辨率图像与低分辨率图像之间的残差(即高频细节),有效缓解了深层网络的训练难题,并提升了性能。
- SRResNet / SRGAN:SRResNet采用了基于ResNet的深度残差网络结构,是纯像素级损失训练的佼佼者。而SRGAN则在SRResNet的基础上,引入了生成对抗网络(GAN)的框架,利用感知损失和对抗损失来生成视觉效果更逼真、细节更丰富的高分辨率图像,虽然可能牺牲部分像素精度(如PSNR),但大幅提升了感知质量。
- EDSR(Enhanced Deep Residual Networks for Super-Resolution):EDSR对ResNet结构进行了优化,移除了批归一化(Batch Normalization)层,并大幅增加了网络深度和参数量,在多个基准测试集上取得了当时最先进的性能,成为后续许多研究的基准模型。
- RDN(Residual Dense Network):RDN结合了残差网络和密集连接网络的优势,通过残差密集块(Residual Dense Block)充分利用所有卷积层的层次化特征,并通过局部特征融合与全局特征融合机制,实现了强大的特征提取与表达能力。
- RCAN(Residual Channel Attention Network):RCAN的核心创新在于引入了通道注意力机制,通过关注信息量更丰富的特征通道,自适应地重新校准通道特征,使得网络能够学习到更多有用的信息,在极深网络(如超过400层)上实现了卓越的性能。
- SwinIR:作为基于Swin Transformer架构的代表性工作,SwinIR将Transformer的强大全局建模能力引入图像复原领域。它利用移位窗口(Shifted Window)自注意力机制,在计算效率和长距离依赖建模之间取得良好平衡,在超分辨率等多种低级视觉任务上展现了强大的性能。
二、人工智能基础软件开发的关键支撑
上述先进模型的实现、训练与部署,离不开成熟的人工智能基础软件栈。其主要环节包括:
- 深度学习框架:如PyTorch、TensorFlow、JAX等,提供了灵活的张量计算、自动微分和动态/静态图构建功能,是研究者实现和实验新模型架构(如注意力机制、Transformer块)的基石。例如,SwinIR的实现高度依赖于框架对自定义模块和复杂计算图的支持。
- 高性能计算库:如CUDA、cuDNN、oneDNN等,为底层矩阵运算和卷积操作提供硬件级优化,是确保训练和推理效率(尤其是对EDSR、VDSR等计算密集型模型)的关键。
- 模型部署与推理引擎:如TensorRT、OpenVINO、ONNX Runtime等,负责将训练好的模型(如轻量化的FSRCNN或复杂的RCAN)优化并部署到各种生产环境(云端、边缘设备、移动端),实现低延迟、高吞吐量的服务。
- 数据处理与管理工具:超分辨率模型训练需要大规模数据集(如DIV2K)。工具如DALI、TFData等可以高效进行数据加载、增强和预处理,而MLflow、Weights & Biases等则用于跟踪实验、管理模型版本和超参数。
- 分布式训练平台:训练深度模型如EDSR、RDN需要海量计算。基于Kubernetes的云原生平台或Horovod等分布式训练框架,能够有效利用多GPU/多节点集群资源,缩短研发周期。
三、与展望
从SRCNN到SwinIR,深度学习模型在超分辨率领域不断向着更深、更智能、更高效的方向演进。模型架构的创新(如残差学习、注意力机制、Transformer)是性能突破的核心。与此人工智能基础软件的持续发展,为这些复杂模型的快速迭代、大规模训练和实际应用落地提供了强大引擎。超分辨率技术将与基础软件更深度协同,向着轻量化、实时化、与高级视觉任务(如检测、分割)联合优化的方向前进,进一步拓宽其在医疗影像、卫星遥感、移动视频等领域的应用边界。